Estimate the graph of conditional dependencies among variables — which ones are related once you account for all the others — by fitting a sparse inverse covariance matrix with a log-determinant objective and an \(\ell_1\) budget.
10.1 The idea
The portfolio chapter (Chapter 9) took a covariance matrix as given. Here we go the other way and estimate it — and specifically its inverse, which carries the more interesting story.
For Gaussian data, the inverse covariance \(S = \Sigma^{-1}\) (the precision matrix) encodes conditional independence: \(S_{ij} = 0\) exactly when variables \(i\) and \(j\) are independent given all the others. So a sparse\(S\) is a sparse graph of direct relationships — often what we actually want to discover. With more variables than the data can pin down, we impose that sparsity directly.
Given i.i.d. samples \(x_i \sim N(0, \Sigma)\) with sample covariance \(Q\), we maximize the Gaussian log-likelihood while capping the total size of \(S\):
The \(\ell_1\) budget \(\alpha \ge 0\) controls sparsity: smaller \(\alpha\) forces more off-diagonal entries to exactly zero. The objective is concave (log_det is concave; the trace term is linear) and the constraints are convex, so CVXR solves it directly.
10.2 Synthetic data with a known answer
So we can check the estimate, we build a true sparse precision matrix \(S_{\text{true}}\), invert it to get the covariance \(R\), and sample from \(N(0, R)\):
set.seed(1)p <-10# number of variablesn <-1000# number of samplesA <-rsparsematrix(p, p, 0.15, rand.x = rnorm)Strue <-as.matrix(A %*%t(A) +0.05*diag(p)) # sparse, symmetric, positive definiteR <-solve(Strue) # the covariance to sample fromx <-matrix(rnorm(n * p), n, p) %*%chol(R) # rows are i.i.d. N(0, R)Q <-cov(x) # sample covariancesum(abs(Strue) >1e-4) # how many true nonzeros (of 100)
[1] 24
10.3 Fit at several sparsity budgets
A semidefinite variable is declared with PSD = TRUE. We sweep \(\alpha\) and, after each solve, zero out numerically negligible entries to read off the recovered pattern:
Note matrix_trace(S %*% Q) rather than sum(diag(S %*% Q)) — same value, but the dedicated atom keeps the expression tree compact. And log_det(S) is its own atom: there is no det() for a CVXR variable, because the log-determinant is the convex object DCP understands.
10.4 What the budget buys
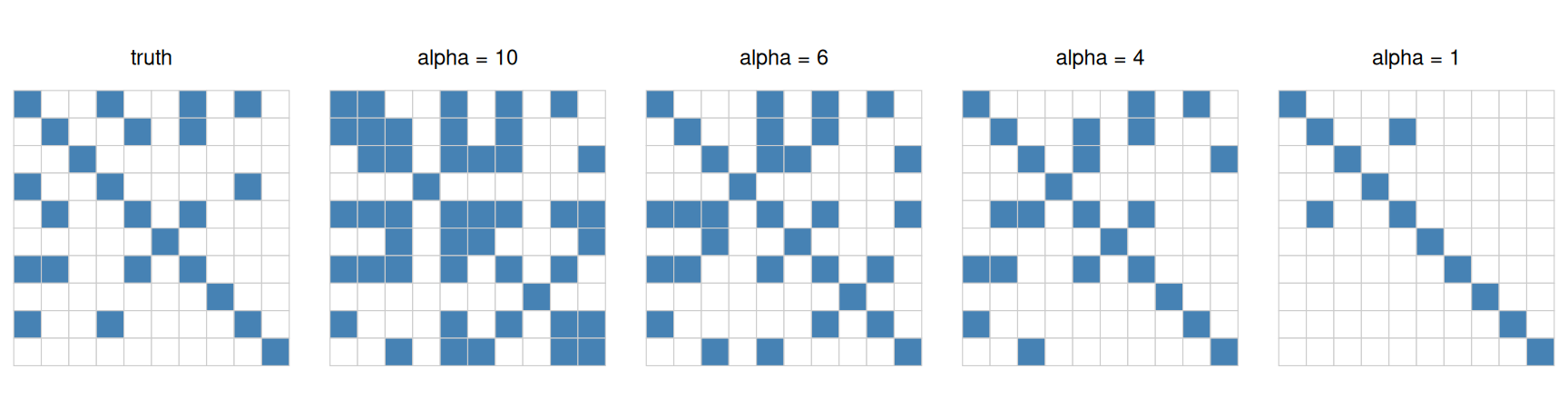
The sparsity pattern of the estimate tightens as \(\alpha\) shrinks. We plot the nonzero mask of the truth alongside each fit:
Nonzero pattern (dark = nonzero) of the true precision matrix and the estimates. Smaller alpha -> sparser. Around alpha = 4 the estimate matches the truth’s sparsity.
At \(\alpha = 10\) the budget is loose and the estimate is dense; as \(\alpha\) falls the off-diagonal entries are squeezed to zero, and near \(\alpha = 4\) the recovered pattern matches the true number of nonzeros. Too small (\(\alpha = 1\)) and we lose real edges. In practice you would pick \(\alpha\) by cross-validation — and because the only thing changing across the sweep is one constant, this is a textbook case for the Parameter trick of Chapter 8.
10.5 Takeaways
The inverse covariance is the object of interest: its zeros are conditional independencies — a graph of direct relationships.
log_det(S) - matrix_trace(S %*% Q) with S declared PSD = TRUE and an \(\ell_1\) budget is the whole model — a few lines of CVXR.
One knob, \(\alpha\), trades density for sparsity; sweep it with a Parameter.